
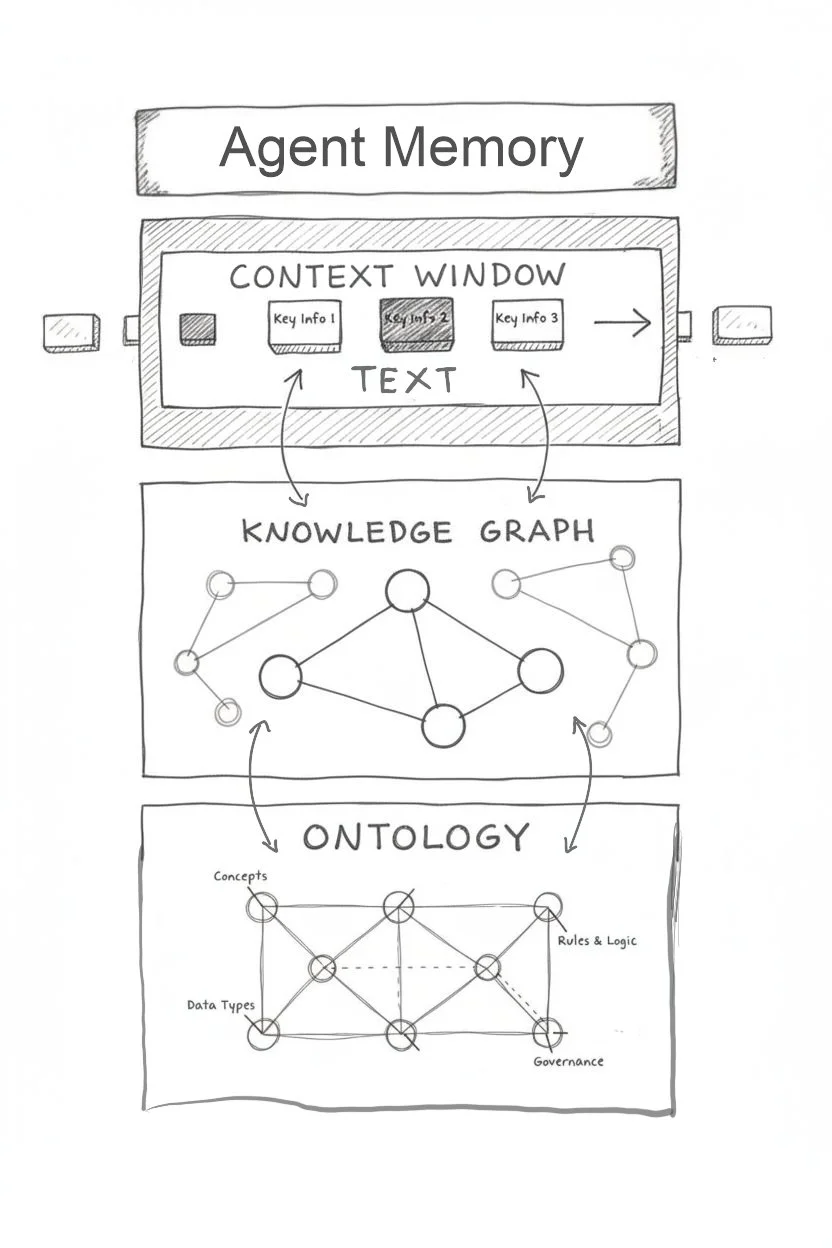
The Quiet Revolution in AI Memory
AI’s next breakthrough isn’t better code generation- it’s memory. As models gain the ability to store, compress, and retrieve context over time, tool use plus memory is turning LLMs into agents.

The Swiss Cheese Problem: Why AI Agents Need Symbolic Backbone
AI agents show superhuman skill yet still fail in simple ways — a paradox known as the “Swiss cheese problem.” The solution lies in neuro-symbolic integration: combining neural networks’ creativity with the rigour of symbolic logic. Knowledge Graphs provide the missing backbone enterprises need for reliable, trustworthy AI.
Why Early Knowledge Graph Adopters Will Win the AI Race
Knowledge graphs are moving from niche to mainstream. Early adopters who embrace ontologies and semantic layers are already seeing measurable business impact. Here’s guidance for building your own successful knowledge graph.
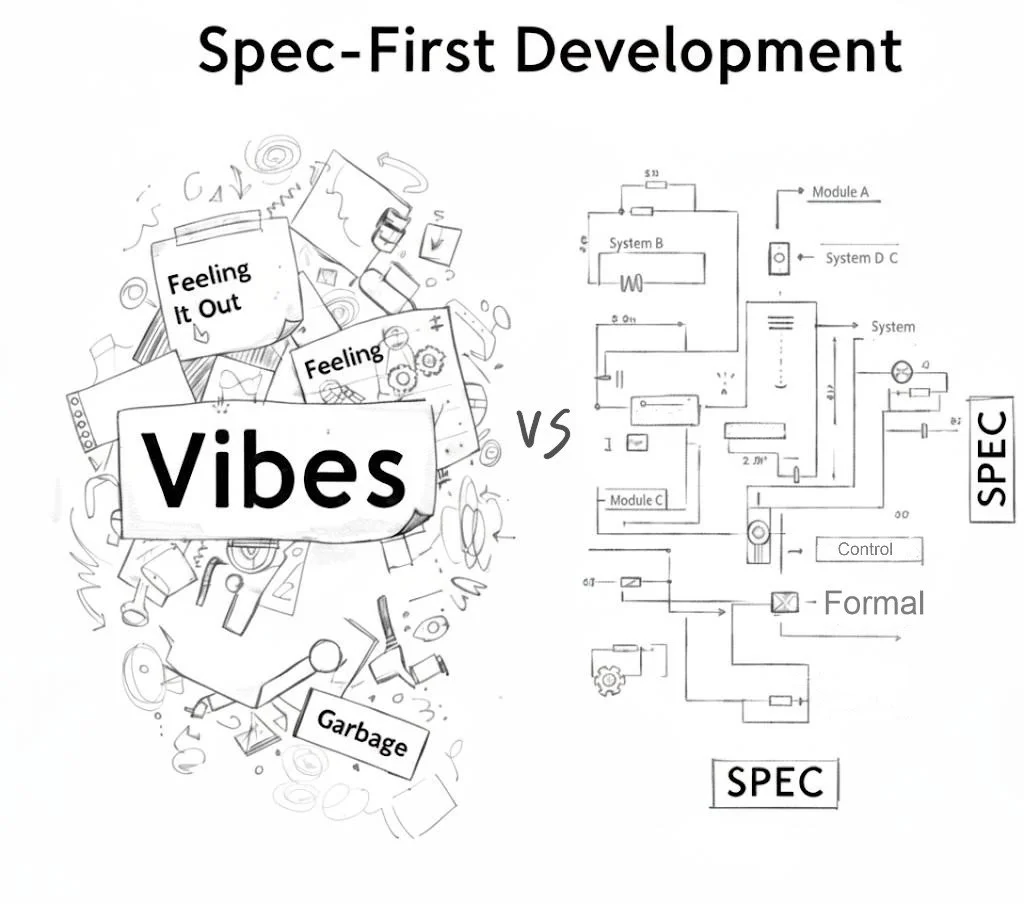
Spec-First Development: Why LLMs Thrive on Structure, Not Vibes
Vibe coding has its thrills, but LLMs shine when paired with formal specifications. Learn how test-driven practices, ontologies, and knowledge graphs turn ambiguity into executable, structured intent.

Context Rot: Why Bigger Context Windows Aren’t the Answer for Retrieval
Bigger context windows don’t automatically improve retrieval. Real gains come from reasoned, precise context—structured and guided by ontologies and knowledge graphs.
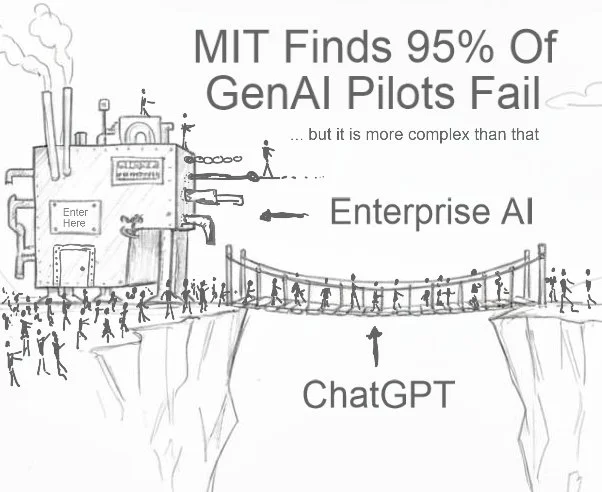
The GenAI Divide: Why 95% of Enterprise AI Pilots Fail
95% of enterprise GenAI pilots fail—but it’s not the models’ fault. The winners connect data, enforce clear semantics, and wrap LLMs in formal ontologies for trustworthy, validated AI.

Integration Isn’t Optional: Why AI-Ready Data Needs URIs and Ontologies
The Semantic Web isn’t the problem—distributed data integration is. For AI agents to act and reason effectively, organisations need clear semantics, stable URIs, and shared ontologies baked into their data products.

Walmart’s SuperAgents: Why Semantics and Knowledge Graphs Are the Real Foundation
Walmart’s SuperAgents highlight the surface magic of AI orchestration. But the real value lies beneath: shared semantics, aligned ontologies, and a long-term investment in knowledge graphs that let agents coordinate reliably.
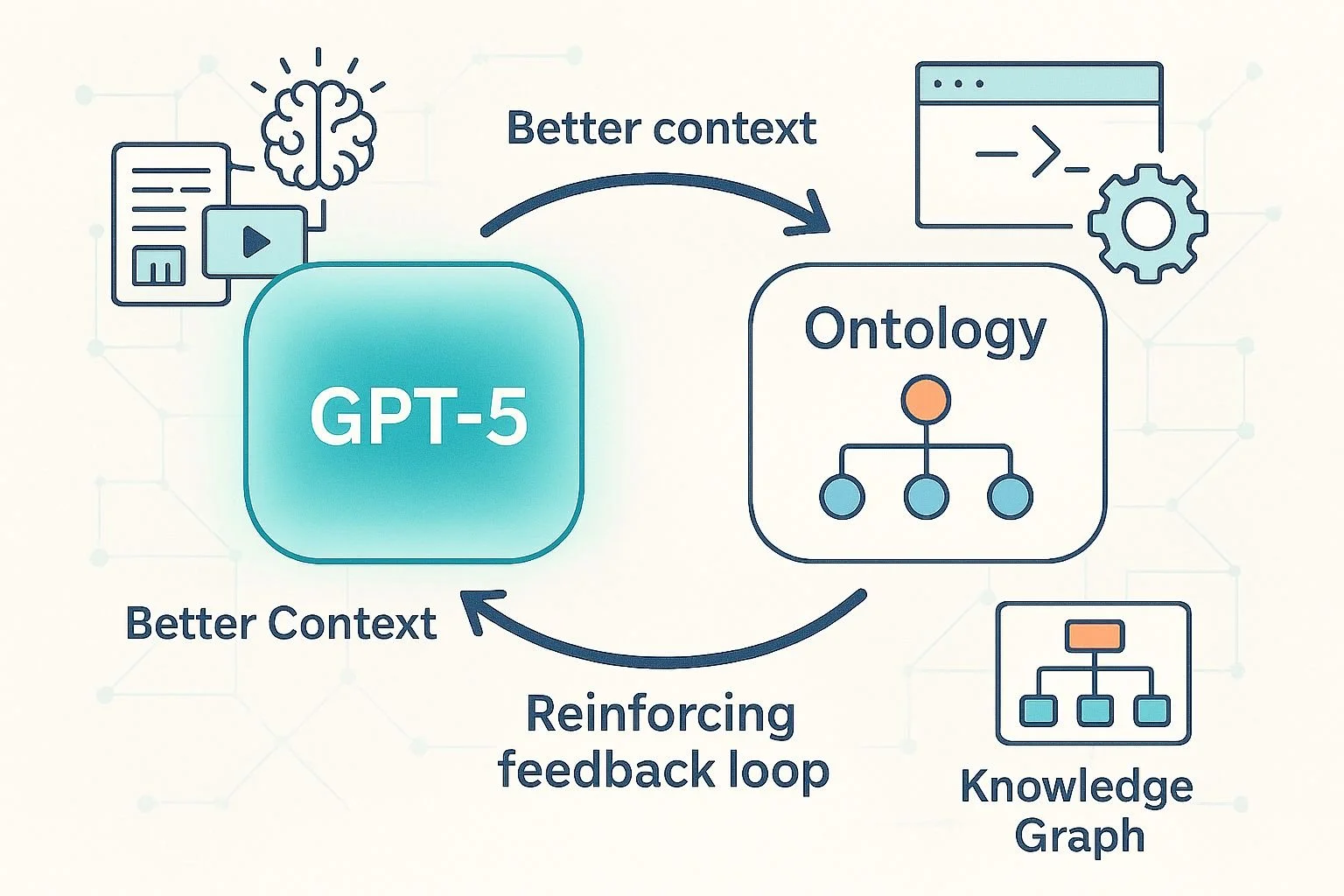
Revisiting the Neural-Symbolic Loop: GPT-5 and Ontologies in Tandem
With GPT-5, the synergy between LLMs and ontologies is clearer than ever. Larger context, multimodal input, and tool use let models help build ontologies — and ontologies, in turn, strengthen LLM reasoning, creating a self-reinforcing loop of improvement.

From Tables to Meaning: Building True Data Products with Ontologies
‘Semantics’ is often misused, yet it defines the very essence of meaning. Large Language Models hold a latent, globalised semantics — but not yours. True differentiation lies in owning your meaning through Knowledge Graphs and ontologies that reflect your reality, not the world’s average.

Semantics Is Meaning: The Hidden Structure That Makes You Unique
‘Semantics’ is often misused, yet it defines the very essence of meaning. Large Language Models hold a latent, globalised semantics — but not yours. True differentiation lies in owning your meaning through Knowledge Graphs and ontologies that reflect your reality, not the world’s average.

From Transduction to Abduction: Building Disciplined Reasoning in AI
Large language models excel at transduction — drawing analogies across cases — and hint at induction, learning patterns from data. But true reasoning demands abduction: generating structured explanations. By pairing LLMs with ontologies and symbolic logic, organisations can move beyond fuzzy resemblance toward grounded, conceptual intelligence.
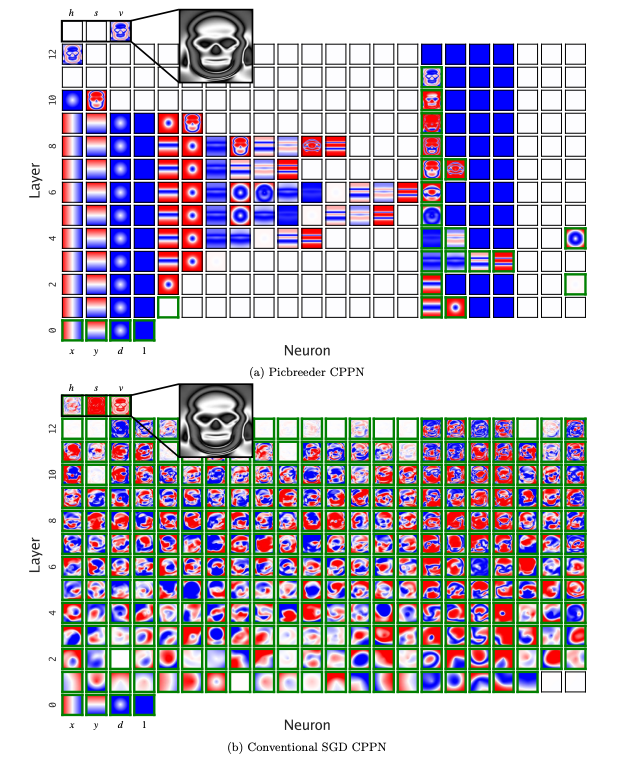
Fractured Intelligence: Why Order Still Matters in AI
Even if large language models grasp deep concepts like symmetry or linearity, their internal representations remain messy and entangled — opaque to human understanding. This lack of structure may limit their ability to generalise far beyond training data. Pairing them with well-organised, ontological frameworks offers a path toward clarity, verifiability, and deeper reasoning.

Co-Creative Intelligence: When AI Agents Help Build Their Own World
AI agents that work with knowledge graphs aren’t just operating inside a static environment — they’re helping to build it. This co-creative relationship mirrors the dynamics of active inference, where intelligence emerges from continuous interaction between beliefs and reality. The real differentiator isn’t better algorithms, but better ontologies — clearer models of the world aligned with organisational strategy.

From Entropy to Intelligence: Redefining Boundaries with Knowledge Graphs
Organisations behave like dissipative systems — optimising locally while exporting entropy to the whole. To become AI-native, we must redraw our boundaries, dissolving silos and integrating intelligence at the organisational level. Knowledge Graphs provide the connective tissue for this transformation, turning chaos into coherence.
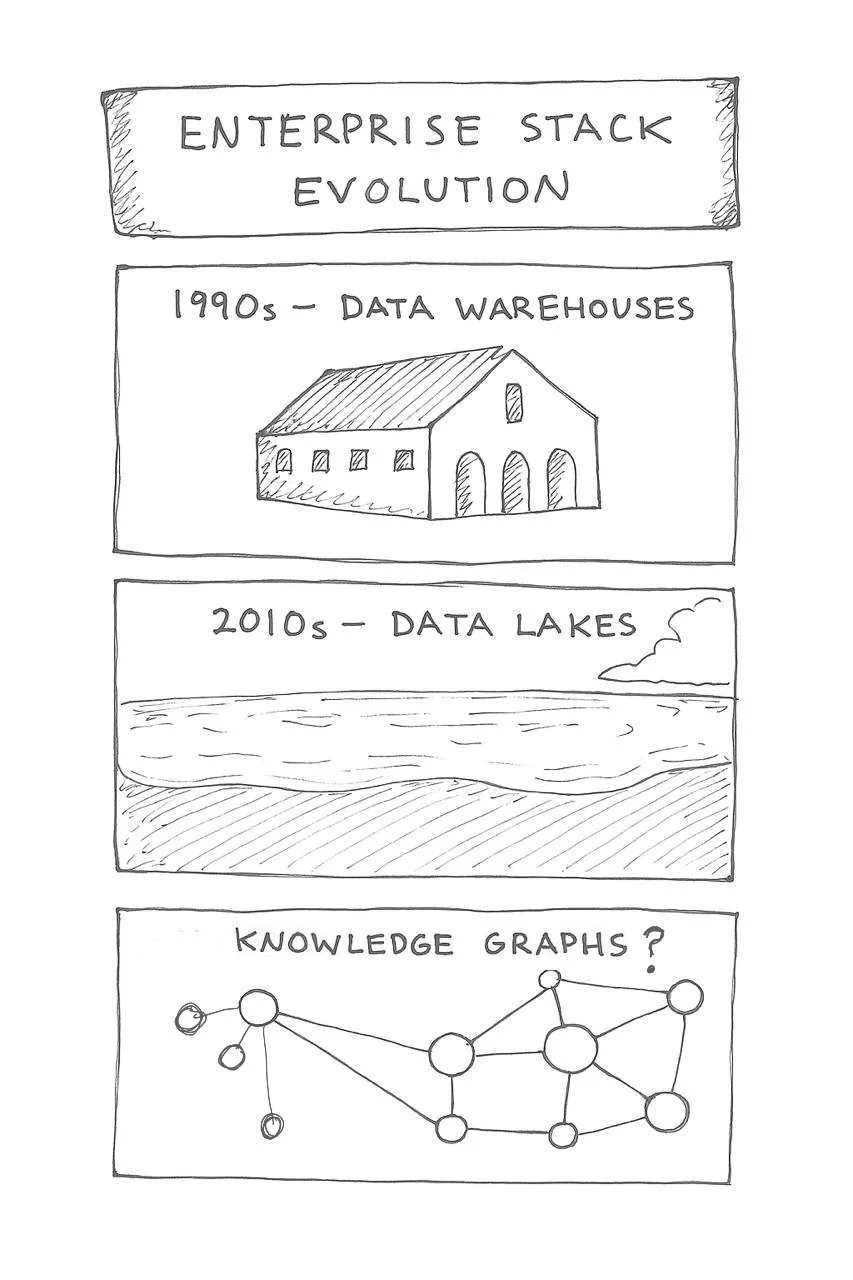
Knowledge Graphs Are Going Mainstream: The New Foundation for AI
From SAP and Netflix to ServiceNow and Samsung, leading organisations are embracing knowledge graphs and ontologies as foundational infrastructure for AI and analytics. The reason is clear: AI needs context, businesses need unified meaning, and users need semantic access to insights. The knowledge graph is becoming the new enterprise standard.

URLs for Data: The Key to Scalable Data Marketplaces
All functioning marketplaces rely on shared standards — and data marketplaces are no exception. The key lies in universal identifiers. Borrowing from the Semantic Web, the use of resolvable URLs for data items offers a simple, scalable way to unify fragmented data estates and enable decentralised coordination across the enterprise.

Head of Data & AI: Reversing the Flow of Intelligence
Forward-thinking organisations are realising that their AI strategy is their data strategy. The next frontier isn’t extracting intelligence from data — it’s embedding intelligence back into it. By using AI to shape, connect, and structure data through ontologies and knowledge graphs, we create systems that truly reflect how the business thinks.

Hairball of Hell
Every graph professional eventually meets the Hairball of Hell — the tangled mess that emerges when beautiful graphs outgrow human perception. While AI can thrive in this complexity, we can’t. The solution isn’t more visualisation; it’s meaning. Ontology acts as a semantic scaffold, helping both humans and machines navigate complexity with purpose.

Philosophy Eats AI
If software is eating the world and AI is eating software, what eats AI? The answer is philosophy—expressed through a clear, machine-readable ontology. By surfacing your enterprise’s core semantics and linking them to real data, you give AI a lens to reason over what truly matters: how your business creates value.
